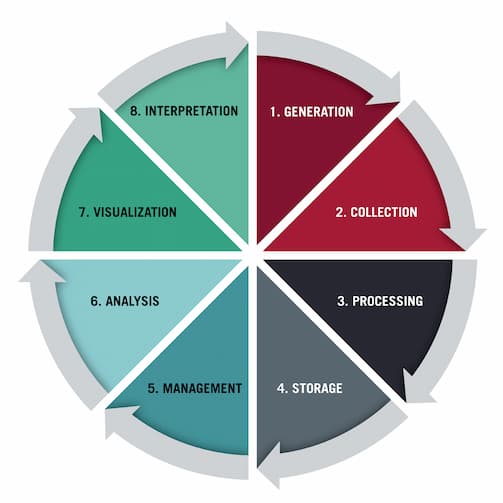
When working with petabyte-scale datasets using distributed frameworks like Hadoop or Spark, what strategies, configurations, or code-level optimizations do you apply to reduce processing time and resource usage? Any key lessons from handling performance bottlenecks or data skew?
When working with petabyte-scale datasets using distributed frameworks like Hadoop or Spark, what strategies, configurations, or code-level optimizations do you apply to reduce processing time and resource usage? Any key lessons from handling performance bottlenecks or data skew?